
Potatoes Cluster: Training a Deep Learning Model Using a 100 Potatoes

Igor Muniz
Director of Artificial Intelligence


Have you ever heard about battery potatoes? Did you know that it is also possible to process information using potatoes? In this post we are going to show you how it’s possible to create a cluster of potatoes, that not only serves as a power supply but also processes data in a very cheap way. With that, we could achieve the performance of a Nvidia GTX 1060 using 100 potatoes connected with nails and clips.
Building the Cluster
In order to build our cluster, we are going to need some other items besides potatoes (we didn’t expect it’s possible to do all this only with potatoes, right?). The following items are necessary to build our cluster:
- 1 Protoboard
- 2 SDRAM module (increase the ram capacity)
- 1 Raspberry pi 4
- Wires
- 100 Potatoes
The raspberry pi will work as the center of our cluster, controlling the data transfer between the SDRAM’s modules and potatoes. The flow is shown below:

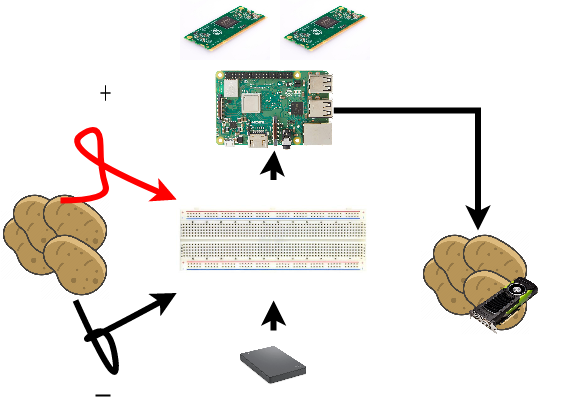
A quick explanation is that it isn’t only possible to use potatoes as power supply but as a processor as well. We can create an electrical circuit inside the potatoes to build a kind of registry (primary thing in a cpu). With those registries, we can store information, transfer it between registries and also perform calculations. In order to do that, we also developed a specific computer language (potato language better saying) for controlling those registries called Pothon (yes, we love Python). We don’t want to extend this post unnecessarily, so we’re publishing a full paper about it in a few days.
The most impressive thing we noticed is that we can increase our potatoes processing speed exponentially by adding more potatoes in our cluster doing parallel connections (is this a new exponential venture?). So in the next section you’re going to see a few benchmarks with different quantities of potatoes, but unfortunately, due to our limited hardware (potatoes), we couldn’t test with more than a hundred. We’re going to leave this as an exercise for the reader.
Development
In order to test our cluster, we developed a very basic deep learning model using Python and Pytorch. This model was trained in both cpu and gpu and all details were recorded so we could do a proper comparison (read next section). We had to do the same model using Pothon and modified version of Pytorch, that doesn’t use cuda cores but carbohydrate cores. Here is a small comparison (please stay tuned for the paper):
from __future__ import print_functionimport argparseimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.optim.lr_scheduler import StepLRclass Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return outputdef train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: breakdef test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))importato potorch importato potorch.nn as nnimportato potorch.nn.functional as Fimportato potorch.optim as optimfrom potorch_vision importato datasets, transformsfrom potorch.optim.lr_scheduler import StepLRclass Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return outputdef train(args, model, device='carbohydrate', train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to('carbohydrate'), target.to('carbohydrate ') optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: breakdef test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to('carbohydrate'), target.to('carbohydrate') output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))As you can see, we adapted Pothon to be very similar to Python being necessary only a few changes in the code. It’s also important to change the device type in order to train using our potatoes. You can find the full code in our Github.
Benchmark
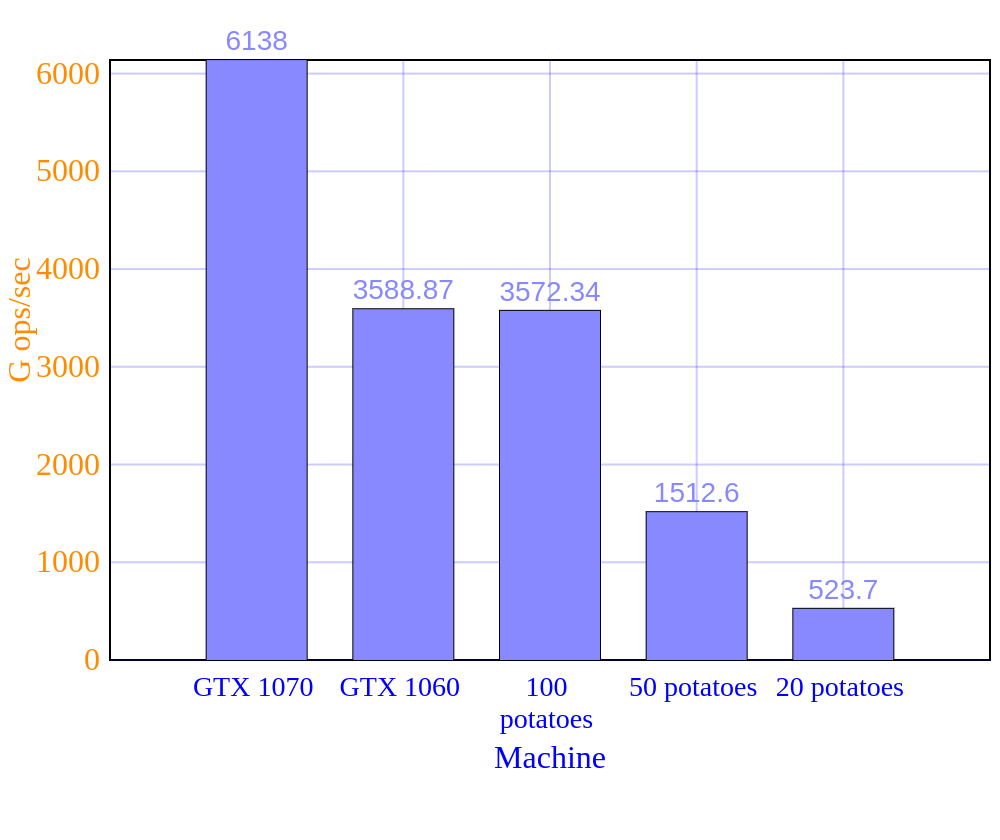
We ran a matrix multiplication of 10000×10000 matrixes as our first benchmark. The cluster took around 0.33 seconds to execute this benchmark in our tests, leading to 3572.34 G ops/sec (Giga operations per second). As a comparison, a computer with an NVidia GeForce GTX 1060 took 0.32 seconds to run the same benchmark.
We then trained a ResNet50 in the MNIST dataset (containing 60 thousand images) as our second benchmark. It took around 72 seconds per epoch (a pass through the whole dataset) to complete the training, while the computer with an NVIDIA GeForce GTX 1060 took 69 seconds. After training for 20 epochs, the accuracy was 98.62% for our cluster and 98.58% for the GTX.
We also ensembled other clusters with different numbers of potatoes. The following chart summarizes our results.

Conclusion
Here are some applications:
- Cryptocoin Mining (BitCoin, DogeCoin, etc…)
- Recommendation Systems
- Objects Detection
- Facial Recognition
We build a cluster 94,85% cheap using potatoes when comparing to the same cluster using a GTX 1060. With such cost reduction, we could save 9 years of future expenses. Now we are buying another building to hold a 35k potatoes cluster. We’re also planning to use Round Red Potatoes, which sounds promising because they can process faster and they’re smaller.
Here’s the link to the project on Github: https://github.com/exponential-ventures/potatoes_cluster Enjoy it!!!
THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
