
Multi-task learning: Solving different computer vision problems with a single model

Igor Muniz
Director of Artificial Intelligence

In the last few years, significant improvements in computer vision were made, making it possible to obtain important information from images. Some of the challenges for a better understanding of a scene are the detection of people and the recognition of the activities they are performing. In this post, I’m going to show a method that I proposed to do a single end-to-end model able to detect people, estimate their pose, and recognize each one of their activities by their pose.

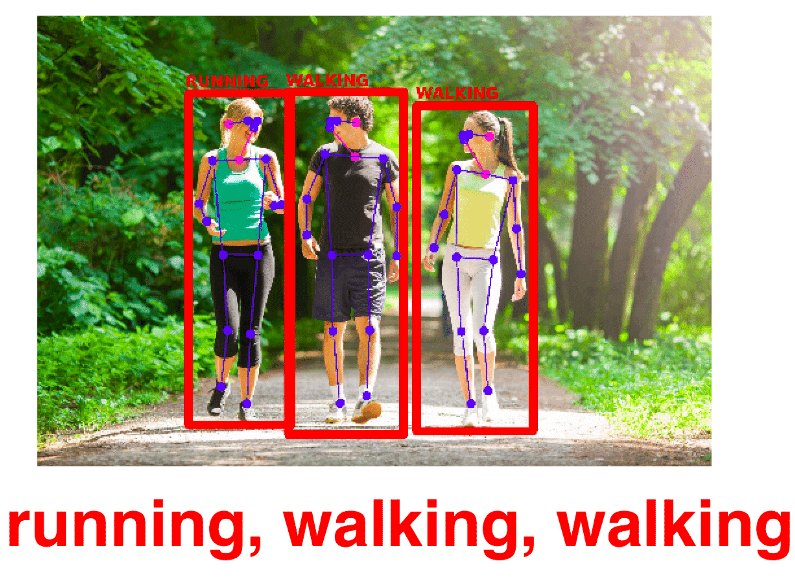
Figure 1: Result of all three tasks learned
Proposed Method
We proposed a single model able to detect people and parts of the body, estimate the pose, and recognize the performed activity of many people in a scene by the estimated pose. All activities share the same backbone (features extractor) given the similarity in the semantics of the problem, making it possible to connect all the networks in a single model with a lower inference time. Fig. 2 depicts the full architecture.

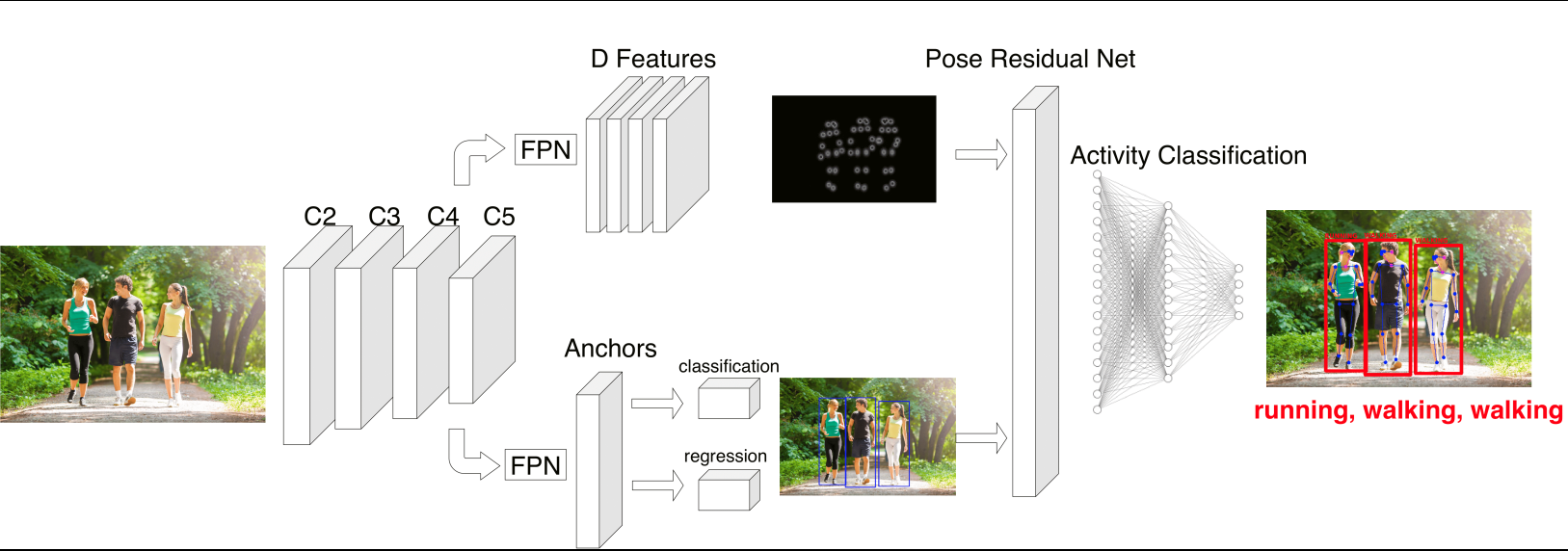
Figure 2: Architecture diagram of the proposed model.
Pose Estimation
The goal of estimating pose in several people is to identify the keypoints of these people in an image. Recognizing these points and identifying these poses is a task of vast complexity, due to the high comprehensiveness of the movements of the human body, variety of clothing, unusual poses, obstruction of the image, and so on.
This work implements a bottom-up method to multi-person pose estimation. The method considers a multi-task learning model which at the end can detect people, detect their keypoints and associate them, and estimate their poses. This model consists of two networks sharing the same backbone, one for person detection and the other for keypoints detection, followed by a residual network for pose correction, called Pose Residual Network [21]. Below I will detail briefly how the model works.
Backbone
In this part of the architecture, input images feature extraction is made. These features are shared and used to train the submodels Keypoint Subnet and Person Detection Subnet.
The backbone is composed of a ResNet [16], a residual network easier to be optimized, and two connected Feature Pyramid Networks [26], one for each submodel. This structure was chosen for the extraction of maps with pyramidal features, making it then possible to represent characteristics in multiple scales, in which all the levels of features generate information useful to the connected models.
Person detection
The network used to detect people is the RetinaNet, in which Lin et al. proposed a new loss function called focal loss, which can deal with the problem of unbalanced classes in the training of objects detectors [25]. Besides being fast and accurate, RetinaNet is compatible with the backbone, applying the FPN network to the ResNet’s last three residual blocks C3, C4, and C5. The model performs convolutional operations to objects classification and bounding box regression from the backbone’s output.
Human keypoints detection
To detect the parts of the human body, we predict the trust map in which each map is the 2D representation of the location of a specific part given a specific pixel. We represent the location of these keypoints as gaussian peaks called heatmaps, in which each heatmap layer belongs to a keypoint standard (e.g., nose, shoulder, wrist, knee).
Consider an image with k people; it has to exist j maps with k peaks, in which j is the number of parts of the human body to be predicted. The network of keypoints detection obtain four pyramidal features P2 − P5 from the ResNet’s last four C2 − C5 blocks, decreasing its depth to 256. For i ∈ {2, 3, 4, 5}, we apply:


where φ is a convolutional layer with a 3 × 3 kernel and 128 filters. The layers D 3 , D 4 and D 5 are redimensioned by 2, 4 and 8, respectively, to equal D 2 space size and then all of them are concatenated in a feature map Z with a depth of 512, smoothed by a 3 × 3 convolutional layer with a ReLU [3] activation. Finally, the heatmap is obtained by a 1× 1 convolution with (j + 1) filters, in which +1 is a background layer containing all of the keypoints.
Pose Residual Network
For each detected person instance, we associate all keypoints within the area delimited by the bounding box. It becomes simple when there is only one person in the area, but in situations of people overlap many keypoints that do not belong to the present instance remain restrained within the delimitations. These excessive points might cause difficulties in the prediction of the final pose. Worrying about the mentioned, Kocabas et al. [21] proposed as a solution to the problem a residual network able to learn the structure of human poses known from their own training dataset. They called this network Pose Residual Network (PRN). That being said, for each keypoint j we have as an input for the network X = {x 1 , x 2 , . . . , x j } in which x j ∈ R W ×H . We expect as output Y = {y 1 , y 2 , . . . , y j }, in which y j ∈ R W ×H , containing the correct positions of the keypoints. The method is described by:

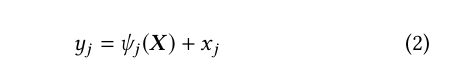
in which ψ j is a correction in the keypoint j. The Eq. 2 is implemented with a residual network of multiple layers, and its output has a function Softmax as activation.
Recognizing Human Actions by Pose
To recognize an action by the person’s pose means to identify patterns in the disposition of the human body parts, which refers to a particular activity. For our model to have this ability, we added an MLP network to the output of the pose of each person, in which the 2D positions of each keypoint works as an input to the classifier.
For each person’s instance and its respective keypoints detected, we normalize the 2D position of the joints between 0 and 1 and link in a way to obtain a [K0 x , K0 y , K1 x , K1 y …, K j x , K j y ] vector with a size of 2∗ j, where j is the total amount of joints. The vector is the input of an MLP model with two intermediate layers with 3072 and 128 nodes each and activation function ReLU, an output layer with n neurons and activation function Softmax, where n is the number of activity classes to be classified. Among all the dense layers we added a Batch-Normalization layer [18] and Dropout [17] with a factor of 0.3.
Training and Implementation Details
We have to train all the parts (keypoints detection, people detection, PRN, and activity classification) separately due to the different loss function in each training. The complete model is obtained by joining these pieces and loading the final weights from each layer.
First, we trained the network for keypoints detection. For this task, we used as input cropped images with a dimension of 480 × 480 centralized in the main person of the scene. For the error calculation and weight update, we generate as ground truth the trust maps from the notes within the dataset of the 2D positions of the keypoints. Each trust map has a Gaussian peak in a certain part of the human body for k people in a scene. Since S ∗ j,k is a trust map for the keypoint j of the person k, we apply the Gauss function in the position of the coordinate x j,k , and then we get the confidence of a localization p with:

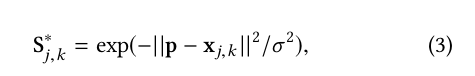
where σ is a value to control the propagation of the peak. The data is augmented during the training time using random rotations around ±40 degrees, scale variation between 0.7 and 1.2, and vertical flip with 30% of probability. We started the training with the weights of the backbone which was previously trained in the ImageNet dataset [9] to facilitate people classification. All the entries are previously processed centralizing the colors at zero in each channel (BGR). To update the weights, we used the loss function L 2 between the predictions and the ground truth maps. Intermediate supervision was also applied to the output of the pyramidal features P to avoid the gradient explosion (vanishing problem) [36]. For i ∈ {2, …, 5} we obtained Z i , applying a 2D convolution with j filters in P i , where j is the amount of keypoints. The layers Z 3 − Z 5 are resized to obtain the same shape as the predicted map. The final loss function is given by:

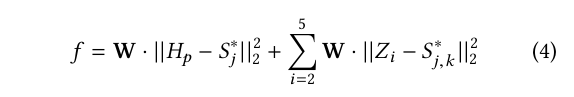
where H p is the output of the network and W is a mask to eliminate in the scene people without annotations. The model is optimized using the Adam function [20] with an initial learning rate of 4e −5 . This rate is updated according to Eq. 5.

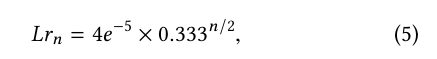
where n ∈ N* is the training epoch number.
In terms of person detection, we used the open source version Keras RetinaNet [13]. The hyperparameters and training details are the same as described in [25]. The output network is then changed to deal only with person detection (one class). The Pose Residual Network is trained with the ground truth data from the dataset itself. For each instance of bounding boxes, we generated an input heatmap with a fixed size of 36 × 56 containing all the delimited joints by that box and an output heatmap, with the same size as the input one, with only the joints of the person concerned. During the training, we used Adam optimizer with a learning rate of 1e −3 and binary cross-entropy loss function.
Concerning the training of the activity classifier, we extracted the pose (joint coordinates) of many people performing a particular activity. To do so, we used the models already trained. These coordinates are the input of the supervised model, in which the output is the activity. We trained with the Adam optimizer and initial learning rate of 1e −3 with a reduction factor of 0.1 on plateau and categorical cross-entropy loss function.
Experiments and Results
For the training and evaluation of the models of pose estimation and person detection, we used the MSCOCO Dataset 2017 [27]. The dataset is divided into a training set, containing 64k images with more than 240k instances of people, and a validation set with 2693 images containing people. It is notorious that the dataset covers 80 classes of distinct objects, and these values refer only to images containing people, which is what matters for us. The used metrics are the official of the COCO competition: average precision (AP) of OKS (object keypoint similarity), for the detection of keypoints, and IoU (intersection over union) for the person detection task.
We used the ResNet architecture as the shared backbone and tested it with three different levels of depth: ResNet50, ResNet101, and ResNet152. To evaluate the model of keypoints detection, we applied test time augmentation using multiple scales in the input image. However, we did not apply a multi-model ensemble approach as done in other studies so a slight difference in the results is expected. The results are shown in Table 1.
Our implementation reached state of the art. We also evaluated the model of person detection, and the results were positive even with the sharing of the backbone with another subnet.


Table 1. Results on MSCOCO validation set.

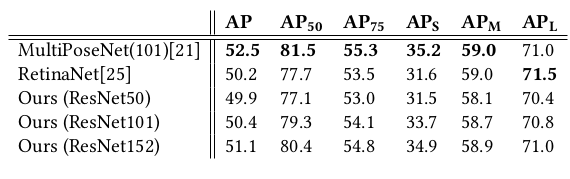
Table 2. Person detection results on MSCOCO validation set
For the task of activity recognition by the estimated pose, we built our dataset from images with categories of determined activities, extracting the poses of people in the scene with the previously trained pose estimation model. We used the MPII Human Pose dataset [4] as a base for activity images, complementing it with images obtained from the internet. We obtained a total of 1204 images with more than 3k people performing four activities: walking, running, sitting, and standing(lack of activity). Each activity has at least 500 examples of poses.
We executed a K-Fold cross validation splitting our data in 20% for validation in 5 different subsets of training and validation. In the end, we calculated as a metric the average between the precision, recall, f1 score, and the accuracy in all of the subsets. We tried different settings for our model. The settings and results are shown in Table 3.

Figure 2: Poses generated with our model

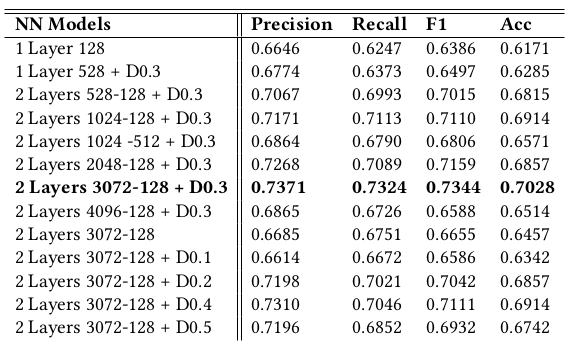
Table 3: Scores of different activity classifiers models.

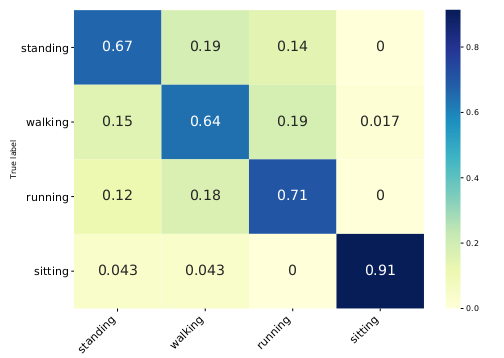
Figure 3: Normalized confusion-matrix of the best model
Conclusion
In this post, we implemented the model of pose estimation MultiPoseNet with state of the art results, and we coupled at the end, a classifier of activity by the pose. We demonstrated
that a single model is capable of estimating the pose and classifying human activity from 2D poses in images containing many people and with real-time inference.
References
[1] [n.d.]. COCO – Common Objects in Context. http://cocodataset.org/#keypoints-leaderboard. http://cocodataset.org/{#}keypoints-leaderboard Accessed: 2019-04-15.
[2] Martín Abadi, Ashish Agarwal, Paul Barham, and et. al. 2015. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. http://tensorflow.org/ Software available from tensorflow.org.
[3] Abien Fred M Agarap. [n.d.]. Deep Learning using Rectified Linear Units ( ReLU ). 1 ([n. d.]), 2–8. arXiv:arXiv:1803.08375v2
[4] Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2014. 2D Human Pose Estimation : New Benchmark and State of the Art Analysis. In IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2014.471
[5] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2017. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In CVPR.
[6] João Carreira and Andrew Zisserman. 2017. Quo Vadis , Action Recognition ? A New Model and the Kinetics Dataset. In IEEE Conference on Computer Vision and Pattern Recognition. 4724–4733. https://doi.org/10.1109/CVPR.2017.502
[7] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. 2018. Cascaded Pyramid Network for Multi-Person Pose Estimation. In IEEE Conference on Computer Vision and Pattern Recognition. arXiv:arXiv:1711.07319v2
[8] François Chollet et al. 2015. Keras. https://keras.io.
[9] Jia Deng, Wei Dong, Richard Socher, Li-jia Li, Kai Li, and Li Fei-fei. 2009. ImageNet : A Large-Scale Hierarchical Image Database. In IEEE Conference on Computer Vision and Pattern Recognition. 2–9.
[10] Georgios Evangelidis, Gurkirt Singh, and Radu Horaud. 2014. Skeletal quads: Human action recognition using joint quadruples. Proceedings – International Conference on Pattern Recognition (2014), 4513–4518. https://doi.org/10.1109/ICPR.2014.772
[11] Mark Everingham, Luc Van Gool, Christopher K I Williams, and John Winn. 2010. The P ASCAL Visual Object Classes ( VOC ) Challenge. International Journal of Computer Vision (2010), 303–338. https://doi.org/10.1007/s11263-009-0275-4
[12] Hao-shu Fang, Shuqin Xie, Yu-wing Tai, Cewu Lu, and Tencent Youtu. 2017. RMPE: Regional Multi-Person Pose Estimation. In IEEE International Conference on Computer Vision. arXiv:arXiv:1612.00137v5
[13] Hans Gaiser, Maarten de Vries, Valeriu Lacatusu, and et. al. 2018. fizyr/keras-retinanet: 0.5.0. https://doi.org/10.5281/zenodo.1464720
[14] Alberto Garcia-Garcia, Sergio Orts, Sergiu Oprea, Victor Villena-Martinez, and José García Rodríguez. 2017. A Review on Deep Learning Techniques Applied to Semantic Segmentation. CoRR abs/1704.06857 (2017).
[15] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. 2013. Vision meets Robotics: The KITTI Dataset. International Journal of Robotics Research (IJRR) (2013).
[16] Kaiming He, Georgia Gkioxari, Piotr Doll, and Ross Girshick. 2017. Mask R-CNN. In IEEE International Conference on Computer Vision. arXiv:arXiv:1703.06870v3
[17] Geoffrey Hinton. 2014. Dropout : A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research 15 (2014), 1929–1958.
[18] Sergey Ioffe and Christian Szegedy. [n.d.]. Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift. ([n. d.]). arXiv:arXiv:1502.03167v3
[19] Shuiwang Ji, Wei Xu, Ming Yang, and Kai Yu. 2013. 3D Convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 1 (2013), 221–231. https://doi.org/10.1109/TPAMI.2012.59 arXiv:1102.0183
[20] Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations. 1–15. https://doi.org/10.1063/1.4902458 arXiv:1412.6980
[21] Muhammed Kocabas, Salih Karagoz, and Emre Akbas. 2018. MultiPoseNet: Fast Multi-Person Pose Estimation Using Pose Residual Network. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 11215 LNCS (2018), 437–453. https://doi.org/10.1007/978-3-030-01252-6_26 arXiv:1807.04067
[22] Alex Krizhevsky and Geoffrey E Hinton. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In International Conference on Neural Information. 1–9.
[23] Y LeCun, B Boser, and D Henderson. 1989. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation 551 (1989), 541–551.
[24] Miaopeng Li, Zimeng Zhou, Jie Li, and Xinguo Liu. 2018. Bottom-
up Pose Estimation of Multiple Person with Bounding Box Constraint. In International Conference on Pattern Recognition. arXiv:arXiv:1807.09972v1
[25] Tsung-yi Lin, Facebook Ai, and Piotr Doll. 2018. Focal Loss for Dense Object Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018). arXiv:arXiv:1708.02002v2
[26] Tsung-yi Lin, Piotr Doll, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie, and Facebook Ai. 2017. Feature Pyramid Networks for Object Detection. IEEE Conference on Computer Vision and Pattern Recognition (2017). arXiv:arXiv:1612.03144v2
[27] Tsung-yi Lin, C Lawrence Zitnick, and Piotr Doll. 2014. Microsoft COCO : Common Objects in Context. In European Conference on Computer Vision. 1–15. arXiv:arXiv:1405.0312v3
[28] Mengyuan Liu and Junsong Yuan. [n.d.]. Recognizing Human Actions as Evolution of Pose Estimation Maps. ([n. d.]).
[29] Diogo C Luvizon, David Picard, and Hedi Tabia. 2018. 2D / 3D Pose Estimation and Action Recognition using Multitask Deep Learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition. arXiv:arXiv:1802.09232v2
[30] Ronald Poppe. 2010. A survey on vision-based human action recognition. Image and Vision Computing 28, 6 (2010), 976–990. https://doi.org/10.1016/j.imavis.2009.11.014
[31] Zhaofan Qiu, Ting Yao, and Tao Mei. 2017. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. Proceedings of the IEEE International Conference on Computer Vision 2017-October (2017), 5534–5542. https://doi.org/10.1109/ICCV.2017.590 arXiv:1711.10305
[32] Sijie Song, Cuiling Lan, Junliang Xing, Wenjun Zeng, and Jiaying Liu. 2017. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. In AAAI Conference on Artificial Intelligence. 4263–4270. https://doi.org/10.1016/B978-0-12-416008-8.00014-0 arXiv:1611.06067
[33] Alexander Toshev. 2014. DeepPose: Human Pose Estimation via Deep Neural Networks. In IEEE Conference on Computer Vision and Pattern Recognition. arXiv:arXiv:1312.4659v3
[34] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. 2018. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2018.00675 arXiv:1711.11248
[35] Chunyu Wang, Yizhou Wang, and Alan L Yuille. 2013. An approach to pose-based action recognition. In IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2013.123
[36] Shih-en Wei. 2016. Convolutional Pose Machines. In IEEE Conference on Computer Vision and Pattern Recognition Shih-En. https://doi.org/10.1109/CVPR.2016.511
[37] Bin Xiao, Haiping Wu, and Yichen Wei. 2018. Simple baselines for human pose estimation and tracking. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 11210 LNCS (2018), 472–487. https://doi.org/10.1007/978-3-030-01231-1_29 arXiv:1804.06208v2
[38] Weilong Yang, Yang Wang, and Greg Mori. 2010. Recognizing Human Actions from Still Images with Latent Poses. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
[39] Zhong-qiu Zhao and Peng Zheng. 2019. Object Detection with Deep Learning : A Review. IEEE Transactions on Neural Networks and Learning Systems (2019). arXiv:arXiv:1807.05511v1
THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
