
Introduction to Serverless on AWS



Today I am going to give a brief introduction on the concepts of creating a basic API using a serverless approach hosted on AWS.
Nowadays a common choice for hosting an API is a virtual machine deployed on a cloud platform such as AWS, Google Cloud or Microsoft Azure. One of the most well known offerings is EC2 by Amazon AWS. There are many advantages to a virtual machine, for starters you do not have to purchase, repair or upgrade any hardware. Also, you do have to worry about down time, since the cloud platform guarantees high availability. Additionally, total cost of ownership of a virtual machine tends to be much lower than that of a physical machine. Finally, in a virtual machine you have access to the root account and can configure it any way you want.
However, that very freedom is often the cause of a lot of drawbacks. To begin with, you are responsible for installing and configuring your database, http server, logging and monitoring utilities and any other software that you may use. Also, this means that you are responsible for keeping your system up to date with security patches and general updates that if forgotten can hinder performance and reliability. On top of this, if you are running a database, for example, it’s up to you to back-up the data and perform a restore in case of an emergency.
The Alternative
An interesting alternative to a virtual machine is a serverless configuration. In this setup, you do not have to manage the server at all. In fact, it is abstracted away such that you do not have access to the OS. You simply consume the resource and any complexities are entirely abstracted away. As a consequence this drastically reduces operational complexity. Another advantage is that you pay for what you use and nothing more. Also, serverless services scale with usage by default. Lastly, a serverless application has high availability and fault tolerance at its core.
Keep in mind that virtual machine solutions (such as EC2) and serverless solutions are by no means the only options. Also, one is not superior to the other. It is simply a matter of which option fits best for the given situation. The solution being developed, expected user demand, expertise of the team and budget all play a role when deciding the best option. With that in mind, I’d like to present to you how to go about using AWS services to implement a basic API with a serverless setup.
The Problem
From here on out we’ll propose a solution using the offerings provided by AWS. And to illustrate how to go about this we’ll discuss the general steps needed to create an API for a basic todo application. Normally, in a setup like this you’d apply a JWT token pattern to secure the endpoints but we’ll skip over those parts. In this application we’d need endpoints to list, create, edit and remove each todo. Additionally, imagine that when creating a Todo a user has the option to upload a single text file. In case that happens, we must save that file in case the user needs it later.
The Solution
To solve this problem we’ll need four different services from AWS: API Gateway, Lambda, S3 and DynamoDB.
The API gateway is, as defined by AWS, a fully managed service that makes it easy to create, publish, maintain, monitor and secure APIs. We’ll use it to create the endpoints, which in our case are simply: GET /todos, POST /todos, GET /todos/{ID}, PUT /todos/{ID} and DELETE /todos/{ID}.
Lambda is a FaaS solution (function as a service). In other words, you write a function and Lambda will execute that function whenever you need and return you the result. In our case, we’ll create a lambda function for each of the endpoints: create, listAll, listOne, edit, delete.
Lambda is fully stateless and therefore after the function executes the memory used is wiped and so we’ll need a location to store our Todos for later retrieval. This is where DynamoDB comes into play, by providing a fully managed NoSql database service. For our example, we’ll need to create a single table that contains our todos.
The last service we’ll need is S3, a cloud storage service. It provides a way to persist files, much like DynamoDb. The difference is that DynamoDb allows you to store data like you would in a noSql database whereas S3 works much like saving a file to the local disk in a folder-like structure. S3 is well suited for persisting binary files and so we are using it to persist our files.
Putting it all Together
To get this to work we’ll create the endpoints we need using the Api Gateway. There we can define resources and multiple methods for each. In that stage we can define the query, path and body parameters that we accept. This way Api Gateway will automatically return a 400 HTTP status if the request is malformed. Additionally, one may define rules to control access to certain endpoints only by certain users. Other possible settings involve defining rate limits and quotas for how often an endpoint may be invoked. However, for our basic example we would not need any of these settings.
The next step is to associate each endpoint with a particular lambda function. This can be achieved when configuring a method of a particular resource as indicated in the image below.


Requests to an endpoint will be routed to the associated lambda and the return of the lambda function will be used as the result of the request. Effectively transforming a lambda into a controller for the endpoint. Once all the connections are made, we’ll have the following:

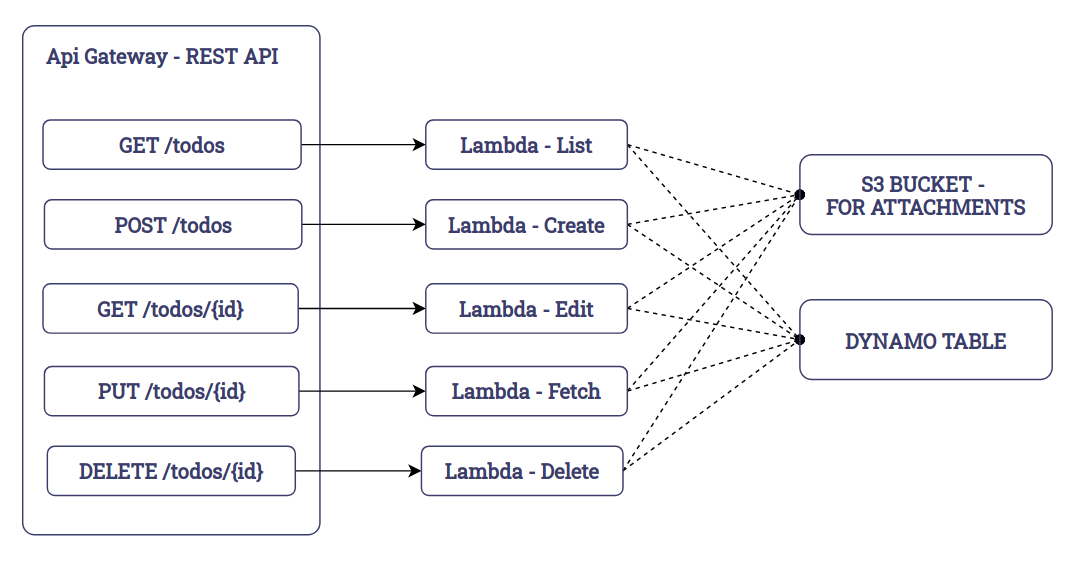
Keep in mind, however, that this arrangement can be done in many different ways. You way define a single lambda to handle all the actions related to a Todo. Then, create multiple javascript functions to keep your code organized like so:

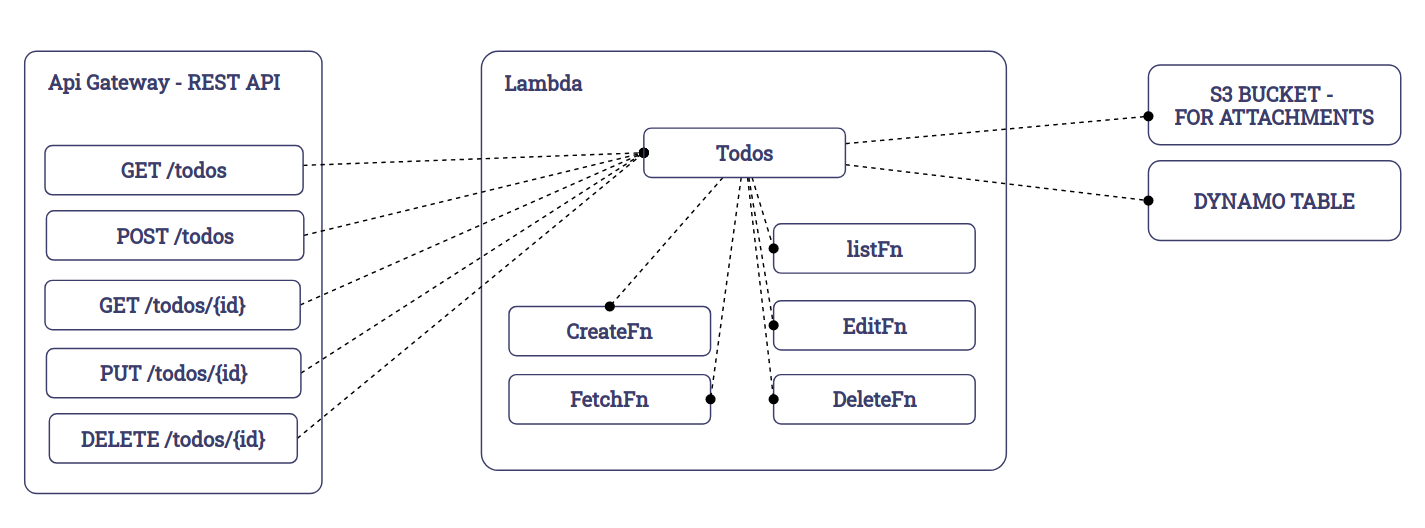
At the end of the day it’s a matter of how you organize your code.
When using lambda with API Gateway the entire request gets sent to the lambda function as a parameter. This includes the http method, query params, body content, headers and other data. Aws will then execute the lambda and return the results to the API Gateway.
To fully implement the logic we’ll need to be able to access our S3 bucket as well as the DynamoDb table from within our Lambda implementation. This way, we’ll be able to add and retrieve todos from the table. Also, this will allow us to save and fetch attachments to our bucket. In order to do this we need to install the AWS SDK. When implementing your lambda function in Node.js this can be done easily by installing the npm package aws-sdk and importing it like so.

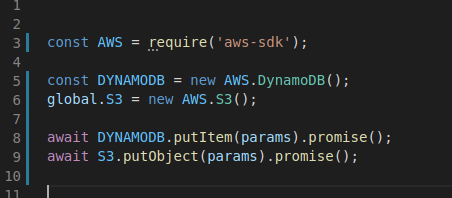
Details of what methods S3 and DynamoDB support can be found here. The process of using these libraries is straightforward.
And that concludes the end of this post! I hope you found this to be useful 😎. In case you would like to get in touch: linkedin.
THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
