
Distributed learning in an on-premise cluster – A Kaggle Reinforcement Learning case

Igor Muniz
Director of Artificial Intelligence


Have you tried any distributed learning algorithms? If you are just starting out in this area, I have my doubts, but if you have been on this path for a few years, you might have faced one of those models. The incredible development of the machine learning area in the last decade has not only brought a new state of the art to several problems but has also taken processing optimization and parallelization to another level. With increasingly larger models, any common machine or even a single super machine may not be enough to achieve the desired result in a reasonable time. Today we will talk about how we could train a reinforcement learning algorithm in a distributed way using our own cluster.

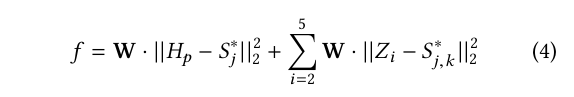
About the problem
Recently Kaggle launched a simulation competition in which the goal was to train agents to master the world’s most popular sport: football. The agents play games against each other, in which the winners receive a score increasing their position on the leaderboard. The complete system simulates a championship making this competition really fun to participate.




Building an agent
Each agent in an 11 vs 11 game controls a single active player and takes actions to improve their team’s situation. As with a typical football game, you want your team to score more than the other side. You only need to control one player at a time and your code gets to pick from 1 of 19 possible actions.
To decide which action to take, you can “teach” your agent in three ways: creating rules, training them in the environment using reinforcement learning, or creating a supervised machine learning model to predict the most likely action at each step.
Rule based bots are basically agents with lots of “ifs” and “else”, that is, a rule created for different scenarios. Although it seems extremely laborious, some rules imposed can perform better than some other learning method.
Reinforcement learning algorithms are concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. They iterate with the environment repeatedly with a single objective: to be able to win the match.
Finally, we can use a supervised machine learning algorithm. But for this to be possible, we intrinsically need data to train our model, being the only way to achieve this by copying the matches of other competitors. For this reason, this technique is commonly called imitation learning, an attempt to create an agent as good as the first placed.
Seed RL
For the competition we ended up trying all three methods, but we will discuss here the reinforcement learning method which was necessary to use an interesting processing distribution solution, the objective of this post.
The chosen algorithm was Seed RL (https://github.com/google-research/seed_rl), a distributed reinforcement learning agent algorithm where both training and inference are performed on the learner which means that we can run the learner in isolation from actors.




This repository contains a script to perform all training locally on one machine and another script capable of distributing the training using Google Cloud machines. Although the latter option is ideal, the training of a reinforcement learning algorithm usually takes a long time, which would make the final cost unfeasible. Since we have our own on premise cluster, we just had to figure out how to distribute this training ourselves.
Our method
First thing to do was to create a configurable script to say what should run in that instance, an actor or the learner. The algorithm itself allowed the two to be executed separately, it was only necessary to keep the execution of each isolated.
The second thing was to create the parameters expected by the learner, such as the number of actors. Since we will distribute an X number of actors on different machines, the learner needs to know how many answers it should expect, that is, the total number of actors being trained simultaneously.
We also had to configure the connection between the learner and each actor over the network, using the gRPC protocol that is already present in the original project. After that we made a shell script responsible for starting the execution of each part of the algorithm, passing the appropriate parameters created.
set -edie () { echo >&2 "$@" exit 1}ENVIRONMENTS="atari|dmlab|football"AGENTS="r2d2|vtrace|sac"[ "$#" -ne 0 ] || die "Usage: run_learner.sh [$ENVIRONMENTS] [$AGENTS] [Num. actors] [Server Port]"echo $1 | grep -E -q $ENVIRONMENTS || die "Supported games: $ENVIRONMENTS"echo $2 | grep -E -q $AGENTS || die "Supported agents: $AGENTS"echo $3 | grep -E -q "^((0|([1-9][0-9]*))|(0x[0-9a-fA-F]+))$" || die "Number of actors should be a non-negative integer without leading zeros"export ENVIRONMENT=$1export AGENT=$2export NUM_ACTORS=$3export SERVER_PORT=$4export CONFIG=$ENVIRONMENTDIR="$( cd "$( dirname "$" )" >/dev/null 2>&1 && pwd )"cd $DIRdocker/build.shdocker_version=$(docker version --format '{{.Server.Version}}')if [[ "19.03" > $docker_version ]]; then docker run --network host -p $SERVER_PORT:$SERVER_PORT --entrypoint ./docker/run_learner.sh -ti -it --name seed_learner --rm seed_rl:$ENVIRONMENT $ENVIRONMENT $AGENT $NUM_ACTORS $SERVER_PORTelse docker run --network host -p $SERVER_PORT:$SERVER_PORT --gpus all --entrypoint ./docker/run_learner.sh -ti -it -e HOST_PERMS="$(id -u):$(id -g)" --name seed_learner --rm seed_rl:$ENVIRONMENT $ENVIRONMENT $AGENT $NUM_ACTORS $SERVER_PORTfiFinally, we put everything inside a docker image and then we just distributed the image over the machines in our cluster. Once all machines had the necessary docker image and startup scripts, we were able to easily orchestrate everything using our kubernetes cluster.
Conclusion
With the recent advances in the machine learning area it is important to know how to distribute the training processing, especially considering the time and money savings.
THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
