
Predicting Reading Level of Texts – A Kaggle NLP Competition

João Paulo Martins
Data Scientist XNV


Introduction:
One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems around the NLP world, and by consequence, trying to make the world a better place.
The Competition:
Can machine learning identify the appropriate reading level of a passage of text, and help inspire learning? Reading is an essential skill for academic success. When students have access to engaging passages offering the right level of challenge, they naturally develop reading skills. If a passage is too easy, the student can get bored, if is too hard the student can quit, so, we need the optimal level of challenge to keep them interested in the reading.
In this competition we were asked to build machine learning algorithms to rate the complexity of reading passages for grade 3-12 classroom use, thus, helping administrators, teachers, and students in their day to day in the classroom.
The results of this competition will be scored on the root mean squared error. RMSE is defined as:

The Dataset:
For this competition the organization provided excerpts from several time periods and a wide range of reading ease scores.
The data has these columns:
- id: unique ID for excerpt;
- url_legal: URL of source;
- license: license of source material;
- excerpt: text to predict reading ease of;
- target: reading ease;
- standard_error: measure of spread of scores among multiple raters for each excerpt.
A curious case in this dataset is that the rating of complexity was made by different people. So, in some cases the standard deviation of rating was very big, showing that even for humans it is hard to reach a consensus about the complexity of a passage.
Our Approach:
As shown in the description of the competition we are dealing with a regression problem. To tackle this, our approach is basically divided in two steps:
1. Further pre-train a Transformer model on competition dataset;
2. Fine tune a Transformer to the regression task of the competition.
Our solution can be better visualized on the diagram below:

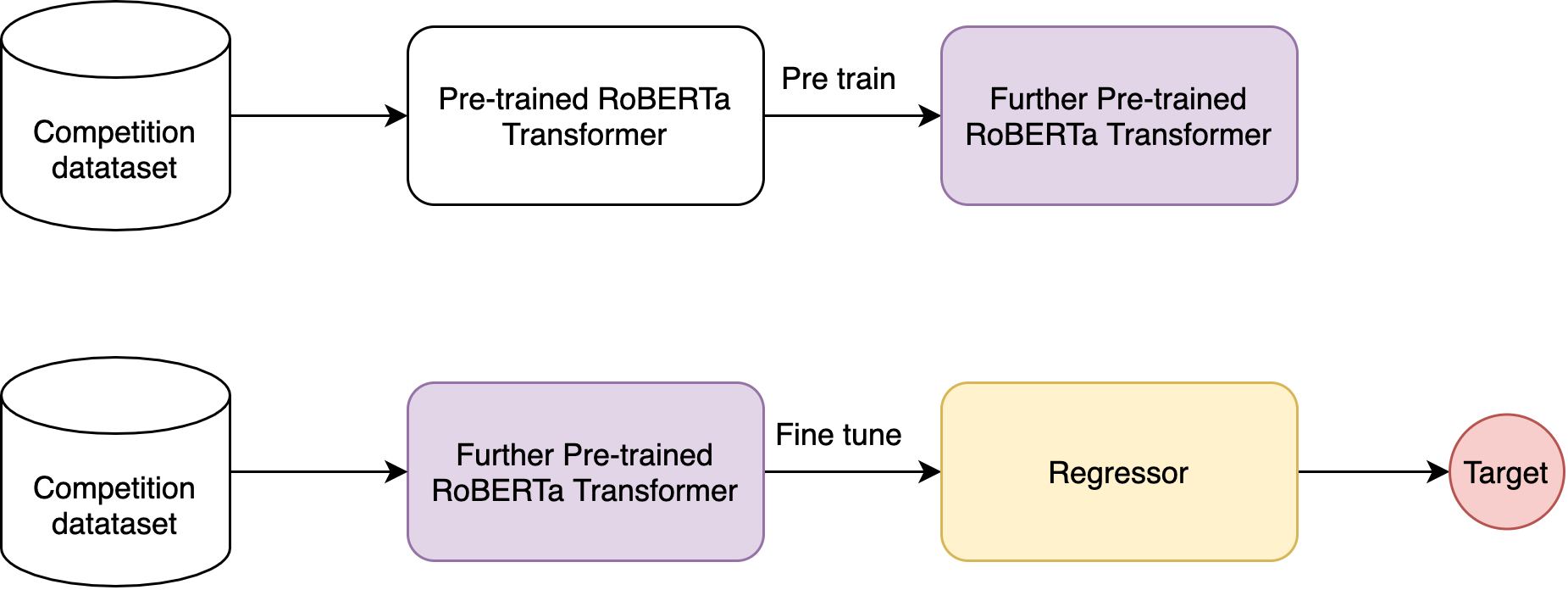
Part 1 – Further Pre-Train Transformer
In this competition, we decided to use a RoBERTa Large and a RoBERTa Base, due to a better performance on the task in hand..
To do the pre-train we use the HuggingFace transformers library in association with our open-source libraries Aurum and Stripping. Together we were able to track every experiment that we made. We pre-train our model for 5, 8 and 10 epochs. The best results for RoBERTa Large were achieved with 8 epochs and for RoBERTa Base the best results were achieved with 5 epochs.
Part 2 – Fine tuning for the task:
Once our transformer models were ready, the second part consisted in the fine tuning for the specific task of rate the complexity of a text passage. To do this we trained a neural network with an attention head and a linear layer predicting the values of target.
To this part, we also used Aurum and Stripping to experiment control and PyTorch Lightning to create the models and for distributed training.
Part 2.1 – The Good Ol’ Classic ML:
One of the approaches, not for fine tuning but for prediction, we trained SVM’s regressors using as input the output of the transformers models. We did that using ScikitLearn library and 5 fold cross validation.
Ensemble and Predictions:
To generate the final submission for the competition we made a weighted ensemble using 4 different models with different settings of pre-trained RoBERTa models and fine tuned regression models. We also used SVM’s as regressors either.
THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
