
VGGNets are back

Igor Muniz
Director of Artificial Intelligence

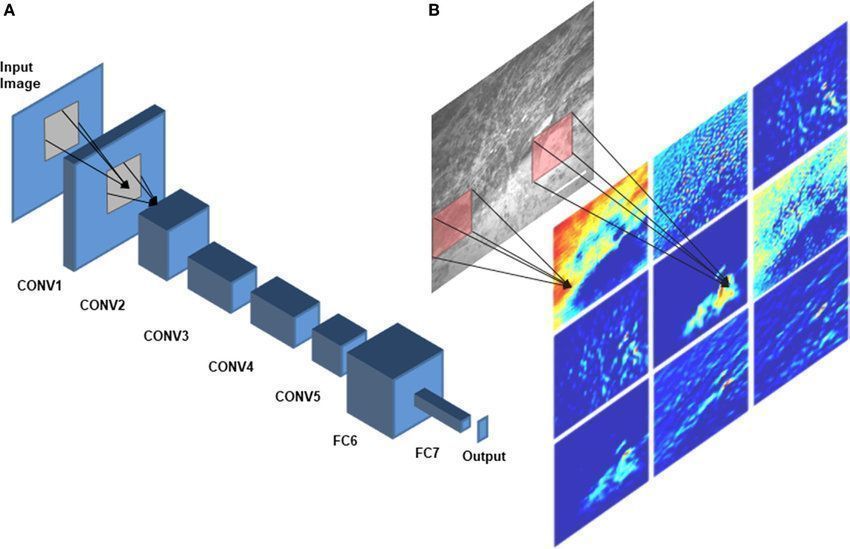
If you have studied the deep learning timeline history, you may know that the big moment was in 2012 when Alex Krizhevsky presented a deep convolutional architecture able to improve the state-of-the-art error on ImageNet dataset by 11%. After that, it was proved that deep learning era had come.


Two years later a better architecture was proposed by Karen Simonyan and Andrew Zisserman from the University of Oxford. In this model, the main difference was the number of layers, where they have stacked more layers creating a deeper model and achieving a better score. A common sense of “deeper is better” appeared and researchers started to increase more and more the number of layers trying to get a new SOTA easily.

However, things started getting complicated and we were not able to improve our models just by putting more layers, which led the Microsoft researchers to develop ResNet, an architecture containing residual connections able to solve the problem of Vanishing Gradient. ResNet article has become the most cited one of human history and all the next architectures have it as reference. By now, you may have understood that VGGNets was not a big deal anymore.
But things have changed this year at the Computer Vision and Pattern Recognition Conference, considered by many to be the largest conference on computer vision and deep learning applications for the field. Ding et al., Chinese researchers, demonstrated that we can continue using VGG-style for inference using only 3×3 convolutions with ReLU, only modification the training architecture creating a multi-branch topology, which makes this model has a state-of-the-art score being faster than a ResNet-50 with higher accuracy. The inference part is obtaining by decoupling those branches and doing re-parametrization, leading to a small sequential model.
For those reasons, the paper was titled “RepVGG: Making VGG-style ConvNets Great Again”. That’s not only a cool name, but an interesting technique that is bringing to me many new ideas. Time to test it!
www.reddit.com/r/MachineLearning/comments/nqflsp/rrepvgg_making_vggstyle_convnets_great_again/
https://arxiv.org/pdf/2101.03697.pdf



THE BLOG
News, lessons, and content from our companies and projects.
41% of small businesses that employ people are operated by women.
We’ve been talking to several startups in the past two weeks! This is a curated list of the top 5 based on the analysis made by our models using the data we collected. This is as fresh as ...



Porto Seguro Challenge – 2nd Place Solution
We are pleased to announce that we got second place in the Porto Seguro Challenge, a competition organized by the largest insurance company in Brazil. Porto Seguro challenged us to build an ...
Adriano Marques
CEO at XNV

Predicting Reading Level of Texts – A Kaggle NLP Competition
Introduction: One of the main fields of AI is Natural Language Processing and its applications in the real world. Here on Amalgam.ai we are building different models to solve some of the problems ...
João Paulo Martins
Data Scientist XNV

Porto Seguro Challenge
Introduction: In the modern world the competition for marketing space is fierce, nowadays every company that wants the slight advantage needs AI to select the best customers and increase the ROI ...
João Paulo Martins
Data Scientist XNV

Sales Development Representative
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...

Rodolfo Egarter
COO @ Pluo

Exponential Hiring Process
The hiring process is a fundamental part of any company, it is the first contact of the professional with the culture and a great display of how things work internally. At Exponential Ventures it ...
Rodolfo Egarter
COO @ Pluo

Exponential Ventures annonce l’acquisition de PyJobs, FrontJobs et RecrutaDev
Fondé en 2017, PyJobs est devenu l’un des sites d’emploi les plus populaires du Brésil pour la communauté Python. Malgré sa croissance agressive au cours de la dernière année, ...
Adriano Marques
CEO at XNV

Exponential Ventures announces the acquisition of PyJobs, FrontJobs, and RecrutaDev
Founded in 2017, PyJobs has become one of Brazil’s most popular job boards for the Python community. Despite its aggressive growth in the past year, PyJobs retained its community-oriented ...
Adriano Marques
CEO at XNV

Sales Executive
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

What is a Startup Studio?
Spoiler: it is NOT an Incubator or Accelerator I have probably interviewed a few hundred professionals in my career as an Entrepreneur. After breaking the ice, one of the first things I do is ask ...
Adriano Marques
CEO at XNV

Social Media
At Exponential Ventures, we’re working to solve big problems with exponential technologies such as Artificial Intelligence, Quantum Computing, Digital Fabrication, Human-Machine ...
Rodolfo Egarter
COO @ Pluo

Hunting for Unicorns
Everybody loves unicorns, right? But perhaps no one loves them more than tech companies. When hiring for a professional, we have an ideal vision of who we are looking for. A professional with X ...
Rodolfo Egarter
COO @ Pluo
Stay In The Loop!
Receive updates and news about XNV and our child companies. Don't worry, we don't SPAM. Ever.
